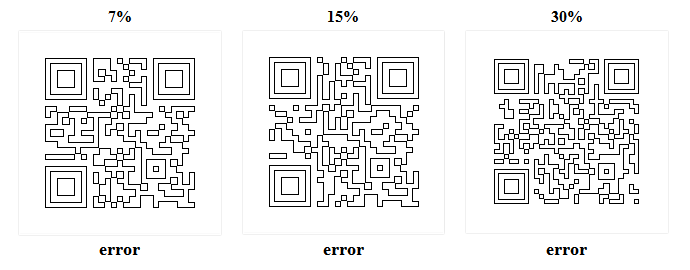
Для коррекции ошибок в QR-коде используется алгоритм Рида-Соломона (Reed-Solomon). Коды имеют четыре уровня коррекции ошибок: : L-7%, M-15%, Q-25%, H-30%. Идея проста: чем больше информации в коде для восстановления (избыточность и дублирование), тем меньше полезной информации. Но зато избыточная информация позволяет восстановить код, когда есть повреждения изображения, пятна и так далее. Все это понимают, но мало кто представляет себе как это все выглядит в реальности. Что допустимо, как может быть серьезно код поврежден, какой характер повреждений и так далее. Найти информацию на эту тему не удалось, поэтому студенческой лабораторией StudLab.com было решено провести
краш-тест для QR-кода с разным уровнем информации для восстановления и разными повреждениями. Ниже представлен один и тот же шаблонный QR-код без помех, ошибок, повреждений для трех уровней: от минимального до максимального.
Будем воздействовать на шаблонные коды с разным уровнем избыточности и оценивать результаты распознавания. Попытаемся хотя бы немного классифицировать повреждения изображения, чтобы можно было составить представление о том, когда код будет работать, а когда нет. Для начала изображение кода было покрыто шумом. Результат неожиданный – нет декодирования, хотя все элементы на коде сохранены.
Дальше коды подверглись расфокусировке с радиусом 2. И тут получаем первый сюрприз – код с самым высоким уровнем надежности не удалось раскодировать. Причина, по всей видимости, в том, что обязательные элементы кода стали меньше по размерам и влияние резкости на них сказалось сильнее. Неожиданность.
Попробуем теперь код немножко стилизовать под рисунок маслом. Сравните картинку внизу и исходные коды. Смотрится красиво и немного необычно. И тут тоже неожиданный результат - декодирование на всех уровнях. Будет полезно дизайнерам.
Истончим линии кода и стилизуем код под рисунок карандашом. Декодировать не удалось.
Продолжаем эксперименты и оформляем коды в виде эскиза, выполнив обработку изображений соответствующим фильтром. Опять ничего не получилось. Не распознается.
Типичный случай искажения изображения – изменение пропорций кода, например, видим код под некоторым углом. Тут все замечательно. Код распознан.
Следующий вариант: заливаем изображение посторонним цветом. Результат отрицательный.
Попробуем зачеркнуть код крест-накрест. Если код разместить где-то в доступном месте, то первое, что придет в голову злоумышленнику – зачеркнуть код. Распознавание не боится зачеркивания. Результат декодирования положительный.
Но мы пробуем все равно зачеркивать, правда уже другим способом – цветом, совпадающим с фоном. И вот совсем неожиданный результат – код не удается декодировать. Сюрприз.
Будем издеваться над кодом дальше. Выгрызем кусочек или закроем чем-то. Не работает.
Ну и в завершение изрисуем QR-код как в голову придет. Код такого варварства не выдержал.
Выводы. Не все так однозначно и просто с информацией для восстановления повреждений. Раз удалось найти хотя бы один случай, когда избыточность кодирования пошла не на пользу, то в алгоритм восстановления надо бы внести изменения. Код оказался очень чувствительным к шуму, а это один из серьезных случаев, встречающихся достаточно часто: туман, дождь, пыль. Не все просто и с зачеркиванием. Тут вообще какие-то странности. Для одного цвета все работате, а для другого нет. Если кому-то вздумается рисовать по коду, то шансы потом его прочитать также ничтожны. В завершение можно заключить, что код достаточно чувствителен к повреждениям и не всегда декодированию помогает наличие избыточной информации.
© StudLab.com: копировать запрещено. Цитировать с активной ссылкой.